moomou
(ノ≧∇≦)ノ ミ ┸┸Listening with LLM
Overview #
This is the first part of many posts I am writing to consolidate learnings on how to finetune Large Language Models (LLMs) to process audio, with the eventual goal of being able to build and host a LLM able to describe human voices.
I am motivated to gain hands-on experience tinkering LLMs so, as much as practical, I tried to recreate utilities and functions with pytorch from scratch rather than rely on 3rd party libraries.
tl;dr I chronicle and share the steps I took to learn how to finetune a LLM model to describe a given audio file on Google’s MusicCaps dataset; you can also find the raw jupyter notebook here
Background #
Recently, I came across two papers
- SALMONN: Towards Generic Hearing Abilities for Large Language Models
- Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
to give LLMs audio understanding capabilities.
Broadly speaking, both papers explored leveraging an audio encoder to transform sound to embeddings that is then fed into LLMs along with text embeddings.
In SALMONN’s case, they combined OpenAI’s Whisper and BEATS encoder, performed pretraining on the combined encoder, then leveraged LoRA for finetuning the LLM. Qwen-Audio bootstrapped its audio encoder from OpenAI’s Whisper; after pretraining, Qwen-Audio performs a full finetuning on the LLM.
These two papers gave me a great overview on how to adapt cross domain encoders and combine them with LLMs. Excited by the idea of a LLM with general audio understanding ability and itching to gain hands-on experience, I decided to try and build a minimal viable LLM with audio processing capability.
Setup #
To get started, I hopped over to HuggingFace to find a good base LLM and a medium-sized dataset. I wanted to do as much work locally as possible so everythign must run on a local RTX 3090.
After testing and comparing a few different models, I settled on Mistral OpenOrca.
For audio encoder, I went with OpenAI’s Whisper.
For dataset, I chose MusicCaps. I did not see any convenient links to download processed/segmented audio files, so I wrote a small script to download the Youtube videos.
One Mini Step at a Time #
With the basic dependencies out of the way, I fired up my Jupyter notebook and started tinkering.
Sampling from Scratch #
The first step I took is to ensure I can load the base LLM and perform inference correctly. Instead of leveraging transformers library’s generation utilities, I implemented my own sampling function to verify my understanding as well as to learn how to sample using embeddings directly, which will come in handy when feeding in audio embeddings.
@torch.no_grad
def sampler(input_ids):
outputs = []
for _ in range(50):
inputs_embeds = model.llm.model.embed_tokens(input_ids)
res = model.llm(inputs_embeds=inputs_embeds)
# res.logits shape is (batch, seq_len, logits)
# sample using multinomial using the last logits
sampled = torch.multinomial(res.logits[:,-1,:].softmax(dim=-1), 1)
# repeatedly concat the `sampled` to the `input_ids` for next sampling
input_ids = torch.cat((input_ids, sampled), dim=-1)
return input_ids
Using the tokenizer class obtained from Transformer’s AutoTokenizer class, I was able to verify sampling worked as expected! Running
tokenizer.decode(sampler(tokenizer("tell me a story", return_tensors="pt").input_ids.to("cuda:0"))[0])
yields (as an example output)
'<s>tell me a story is a film and video production company, tell me a story is a concept that was created to allow people to come together through the power of storytelling.\n and so, with this massive power in storytelling, the founders and creat'
Debugging NaNs and Infs #
So far so good. However, I soon noticed that, occasionally, the sampling function would fail by complaining that softmax function encountered an inf or NaN. I followed this insightful thread and learnt to identify the source of NaN by using the following adapted Pytorch hooks
import torch
from functools import partial
__registered_hook_refs = []
for h in __registered_hook_refs:
h.remove()
__global = []
def nan_hook(module, args, output, name=None):
if not isinstance(output, tuple):
outputs = [output]
else:
outputs = output
for i, out in enumerate(outputs):
if out is None:
continue
if isinstance(out, tuple):
for j, out2 in enumerate(out):
nan_mask = torch.isnan(out2)
if nan_mask.any():
__global.append((module, args, output))
raise RuntimeError(f"In module {name} of name {module.__class__.__name__}, Found NAN in output {j} at indices: ", nan_mask.nonzero(), "where:",
out[nan_mask.nonzero()[:, 0].unique(sorted=True)])
elif torch.is_tensor(out):
nan_mask = torch.isnan(out)
if nan_mask.any():
__global.append((module, args, output))
raise RuntimeError(f"In module {name} of name {module.__class__.__name__}, Found NAN in output {i} at indices: ", nan_mask.nonzero(), "where:",
out[nan_mask.nonzero()[:, 0].unique(sorted=True)])
def register_nan_hook(model: torch.nn.Module):
for name, submodule in model.named_modules():
new_hook = partial(nan_hook, name=name+'.back')
hook_ref = submodule.register_full_backward_hook(new_hook)
__registered_hook_refs.append(hook_ref)
new_hook = partial(nan_hook, name=name+'.fwd')
hook_ref = submodule.register_forward_hook(new_hook)
__registered_hook_refs.append(hook_ref)
debug = True
register_nan_hook(model) if debug else None
Leveraging these hooks narrowed down the source of issue to a particular layer and from there I was able to trace the problem to an inf value in the model weights. Digging further, I traced the source of inf to bad RAM sticks! After mitigation, I wrote a small script to verify the model weights and confirmed sampling function worked as expected.
# verify model weight
from collections import Counter
pbytype = Counter()
for name, p in (model.named_parameters()):
if torch.isinf(p).any() or torch.isnan(p).any():
print(name, p)
raise ValueError("invalid weight")
else:
pbytype[p.dtype] += 1
print("OK", pbytype)
Adapting Whisper to Mistral #
After gaining confidence with debugging Pytorch modules, I focused on adapting Whisper model so audio files can be transformed into an embedding that can then be fed into Mistral.
OpenAI’s Whisper model is composed of two major components, an AudioEncoder and a TextDecoder.
For the purpose of translating audio into embeddings, I only need the AudioEncoder component.
Therefore, I loaded up a full Whisper model and extracted the AudioEncoder weights using the following snippets
import whisper
model = whisper.load_model("large-v3")
audio_encoder = model.encoder
torch.save(
audio_encoder.state_dict(),
"<output_location>",
)
I adapted the Whisper AudioEncoder into a TunableWhisperAudioEncoder with an extra projection layer to map from Whisper’s audio embedding (size 1280) to mistral’s token embedding (size 4096).
I ensured proj is the only trainable network by explicitly freezing the audio encoder’s parameters. Note that TrainableSubmodule is a hyperparameter and any model that maps the output embedding to size 4096 will work. Later in the post, I will describe what I found to work for me.
class TunableWhisperAudioEncoder(nn.Module):
def __init__(self, *, output_embedding_size=4096):
"""
args
output_embedding_size: int = 4096 / mistral default embedding size
"""
super().__init__()
self.audio_encoder = load_whisper_v3_audio_encoder()
self.proj = TrainableSubmodule(output_embedding_size=output_embedding_size)
# # Freeze all parameters
for param in audio_encoder.parameters():
param.requires_grad = False
def forward(self, mels):
res = self.audio_encoder(mels)
res = self.proj(res)
return res
def load_whisper_v3_audio_encoder(
*,
n_mels=128,
n_audio_ctx=1500,
n_audio_state=1280,
n_audio_head=20,
n_audio_layer=32,
):
m = whisper.model.AudioEncoder(
n_mels, n_audio_ctx, n_audio_state, n_audio_head, n_audio_layer
)
m.load_state_dict(torch.load(WHISPER_AUDIO_BIN))
return m
Finally, I build up the model I am going to use for training as follows
class Model(nn.Module):
def __init__(self, audio_encoder: "Whisper.AudioEncoder", llm: "Mistral"):
super().__init__()
self.audio_encoder = audio_encoder
self.llm = llm
# freeze the LLM weights
for p in self.llm.parameters():
p.requires_grad = False
def forward(self, batch):
audio_mels = batch["audio_mels"]
# caption token ids
cap_ids = batch["cap_ids"]
# caption attention mask
cap_ids_attention_mask = batch["cap_attention_mask"]
prompt_ids = batch["prompt_ids"]
prompt_ids_attention_mask = batch["prompt_attention_mask"]
end_prompt_ids = batch["end_prompt_ids"]
end_prompt_ids_attention_mask = batch["end_prompt_attention_mask"]
audio_embeds = self.audio_encoder(audio_mels)
# audio_embeds: (batch, audio_seq_len, audio_embedding_size)
bs, audio_seq = audio_embeds.shape[:2]
attention_mask = torch.concat(
(
prompt_ids_attention_mask,
torch.ones(bs, audio_seq).to(cap_ids.device),
end_prompt_ids_attention_mask,
cap_ids_attention_mask,
),
dim=1,
)
cap_embeds = self.llm.model.embed_tokens(cap_ids)
prompt_embeds = self.llm.model.embed_tokens(prompt_ids)
end_prompt_embeds = self.llm.model.embed_tokens(end_prompt_ids)
# build the inputs_embeds by concating all the token embeddings
# with audio_embeddings
inputs_embeds = torch.concat(
(
prompt_embeds,
audio_embeds.to(cap_embeds.dtype),
end_prompt_embeds,
cap_embeds,
),
dim=1,
)
mout = self.llm(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
)
return mout, audio_embeds.shape[1]
The model itself is quite simple in that it simply holds reference to the Mistral LLM and TunableWhisperAudioEncoder. The forward method encapsulates the logic of converting audio mel-spectrogram into audio embeddings, then concatenating the audio embeddings with text/token embeddings to feeding those into Mistral LLM.
Sampling with Audio from Scratch #
With the basic model in place, the next step is to try and sample from this model with audio inputs. Here is the audio sampling function I came up with.
# note, full gist is available at https://gist.github.com/moomou/7df8345d79a0063d67d1fa2b4cf55db8
@torch.no_grad()
def sample_with_audio(model, tokenizer, prompt, audio_file, device="cuda:0", iteration=50):
audio_mels = load_audio_mels(audio_file).to(device).half()
end_prompt_ids, end_prompt_attention_mask = text_2_ids_and_attention_mask(
tokenizer,
end_template(),
truncate=True,
)
prompt_ids, prompt_attention_mask = text_2_ids_and_attention_mask(
tokenizer,
prompt,
)
prompt_ids = prompt_ids.to(device)
prompt_attention_mask = prompt_attention_mask.to(device)
end_prompt_attention_mask = end_prompt_attention_mask.to(device)
end_prompt_ids = end_prompt_ids.to(device)
sampled_ids = None
prompt_embeds = None
end_prompt_embeds = None
audio_embeds = None
with torch.amp.autocast(device_type="cuda", dtype=torch.float16): # use float16 to reduce GPU memory
if audio_embeds is None:
audio_embeds = model.audio_encoder(audio_mels)
bs, audio_seq = audio_embeds.shape[:2]
mask_concat_args = [
prompt_attention_mask,
torch.ones(bs, audio_seq).to(audio_embeds.device),
end_prompt_attention_mask,
]
for _ in range(iteration):
if sampled_ids is not None:
mask_concat_args.append(torch.ones(bs, sampled_ids.shape[1]).to(audio_embeds.device))
attention_mask = torch.concat(
tuple(mask_concat_args),
dim=1,
)
if prompt_embeds is None:
prompt_embeds = model.llm.model.embed_tokens(prompt_ids)
if end_prompt_embeds is None:
end_prompt_embeds = model.llm.model.embed_tokens(end_prompt_ids)
sampled_ids_embeds = None
if sampled_ids is not None:
sampled_ids_embeds = model.llm.model.embed_tokens(sampled_ids)
embeds_concat_args = [
prompt_embeds,
audio_embeds.to(prompt_embeds.dtype),
end_prompt_embeds,
]
if sampled_ids_embeds is not None:
embeds_concat_args.append(sampled_ids_embeds)
inputs_embeds = torch.concat(
tuple(embeds_concat_args),
dim=1,
)
mout = model.llm(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
)
logits = mout.logits
sampled = torch.multinomial(logits[:, -1, :].softmax(dim=-1), 1)
if sampled_ids is None:
sampled_ids = sampled
else:
sampled_ids = torch.cat((sampled_ids, sampled), dim=-1).to(device)
return torch.concat((
prompt_ids,
end_prompt_ids,
sampled_ids,
),dim=-1)
Putting the function to use via
dataloader = ... # standard pytorch dataloader
local_batch = next(iter(dataloader))
tokenizer.decode(sample_with_audio(model, tokenizer, prompt_template_fn(), audio_file, iteration=60)[0])
produces gibberish as expected since TunableWhisperAudioEncoder projection layer is untrained.
'<s> <|im_start|> system\n You are a helpful AI who follows instruction carefully<|im_end|> <|im_start|> user\n Describe the sound of the given file \n <|im_end|> <|im_start|> assistant\n war<|im_end|> clockunits ]andfirst4Iftektime爆R Cur<|im_end|> United<|im_end|> ’daysIn“Never<|im_end|> thenAnd,and VI<|im_end|> Islo<|im_end|> GOkaydown<|im_end|> JainteYoulfailedLabelsEvenfacevC,rest<|im_end|><|im_end|><|im_end|><|im_end|> q<|im_end|> Xs<|im_end|> h<|im_end|><|im_end|>'
Defining Loss Function #
The loss function here is the standard cross entropy loss on the logits output; the only trick is that the loss should only be calculated on the caption portion. Specifically,
# calculate loss
# local_batch: (b, seq, C)
prompt_ids_seq = local_batch["prompt_ids"].shape[1]
end_prompt_ids_seq = local_batch["end_prompt_ids"].shape[1]
logits_start = prompt_ids_seq + audio_seq + end_prompt_ids_seq
# remove the last output
logits = ... # model output
# remove the prompt and audio seq from logits
# calculation; additionally, remove the final item
logits = logits[:, logits_start:-1, :].contiguous()
# calculate target using only `cap_ids`
targets = batch["cap_ids"][:]
targets = targets[:, 1:]
loss = nn.functional.cross_entropy(
logits.view(-1, logits.shape[-1]), targets.view(-1)
)
Training, Overfitting and Debugging Gradients #
Finally, all the pieces are in place for training the model. The objective I had in mind is to make the frozen LLM describe a given audio file by training only TunableWhisperAudioEncoder; achieving this will not give LLM general audio understanding ability since the training data is small but will give me great confidence that I performed all the basic steps right.
In order to ensure training is setup correctly, I started small and one step at a time. Specifically, I interactively stepped through the training steps manually, recorded and plotted the weight update relative to weight data in TunableWhisperAudioEncoder, and ensured there is no inf or NaN using the Pytorch hooks described previously. These steps were repeated for varous combination of learning rate, model architecture, and optimizer.
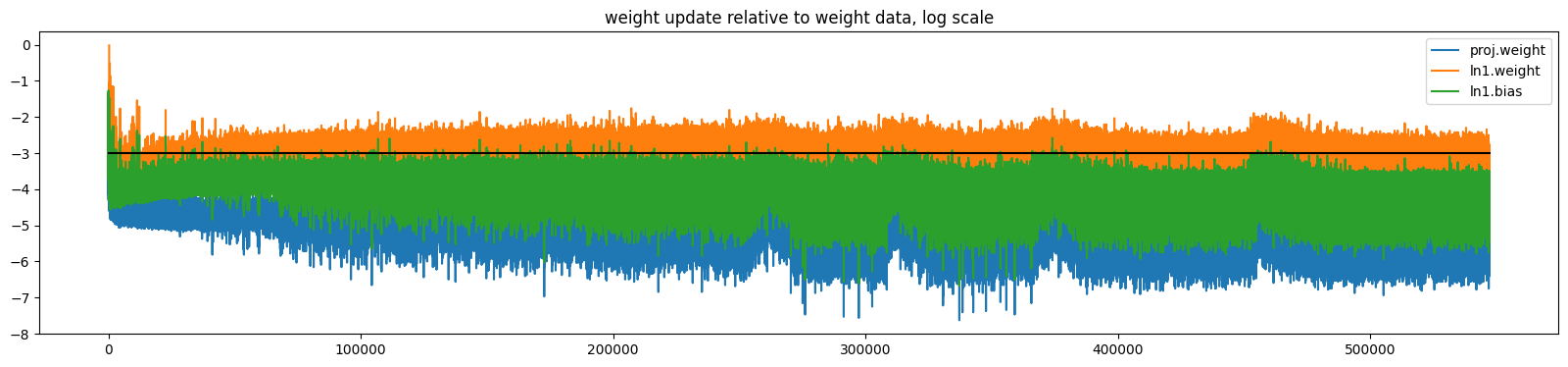
Keeping the setup as simple as possible, I found Adam (without momentum), a constant learning rate of 1.5e-3, and using the following simple TrainableSubmodule, I achieved stable training.
class TrainableSubmodule(nn.Module):
def __init__(self, output_embedding_size=4096):
super().__init__()
self.pool = nn.AdaptiveAvgPool1d(250)
self.proj = nn.Linear(1280, output_embedding_size, bias=False)
self.ln1 = nn.LayerNorm(1280)
I ran training over the course of ~4days and by the time I stopped training, the loss was still going down. By the time I stopped, I achieved ~0.46 loss, which translates to approximately 66% probability for the correct token!
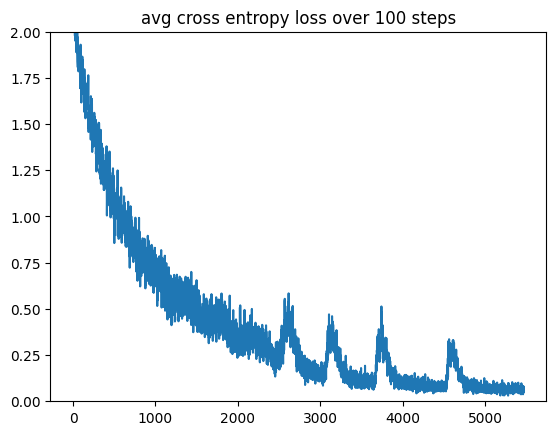
Rerunning the sample_with_audio with the same audio file that produced gibberish pretraining, I now obtain
"<s> <|im_start|> system\n You are a helpful AI who follows instruction carefully<|im_end|> <|im_start|> user\n Describe the sound of the given file \n <|im_end|> <|im_start|> assistant\n The electronica song features a crisp acoustic kick, snap snare and hat along with a deep bass. The male vocal is rapping syncopated along with a male background vocal. The song is fast paced and there is a limited frequency range of the synths. The song"
Compare this against the ground truth
"This is a K-pop music piece performed by a boy band. Initially, a male vocalist is singing in a rap-like manner. Then, it switches to another male vocal that is singing more melodically. The melody is being played by a crisp synth sound. The rhythmic background consists of an energetic electronic drum beat. There is a danceable feel to it. This piece could be playing at Korean nightclubs and dance clubs."
The result is pretty good!
It’s worth repeating this is achieved by only training on the audio encoder projection without modifying the LLM weights or the Whisper AudioEncoder weights.
Next Steps #
With the fundamentals in place, I am planning to scale up training by incorporating more audio tasks such as transcription, speaker identification, etc. as well as apply finetuning to LLM to work my way toward replicating “emergent” behaviors described in the referenced papers.
Assuming sufficient data and with a proper training regime, LLM should be able to perform original audio tasks such as say identify the speaker age or gender without having been explicitly trained on such task.
More work to be done!
Acknowledgement #
I would not have been able to do any of this without learning from the excellent lectures by Karpathy.